 DE
DE EN
EN
Große Sprachmodelle (LLMs, large language models) haben seit dem ChatGPT Moment im November 2022 für große öffentliche Aufmerksamkeit gesorgt. In der Fachwelt hat aber schon 2012 der sog. ImageNet Moment, bei dem ein Bilderkennungssystem mittels maschinellem Lernen erstmals deutlich besser als hand-optimierte Algorithmen bei einem bekannten Test abgeschnitten hat, den Startschuss für ein beispielloses Wettrennen um immer bessere Modelle gegeben, die in immer mehr Disziplinen und Aufgaben Ergebnisse auf dem Niveau durchschnittlicher Menschen erreichen. Egal ob Spracherkennung, Sprachsynthese, Textverständnis, Bildverständnis oder Bildgenerierung. Überall werden die Ergebnisse kontinuierlich und häufig dramatisch besser. Audio, Text und Bild werden als verschiedene Modalitäten betrachtet. Nachdem in jeder Disziplin für sich genommen trotz verbleibender Defizite schon sehr gute Leistungen erzielt werden, ist der nächste Schritt jetzt die verschiedenen Bestandteile zu einem einzigen großen Modell zu kombinieren. Das menschliche Gehirn dient dabei als Vorbild.
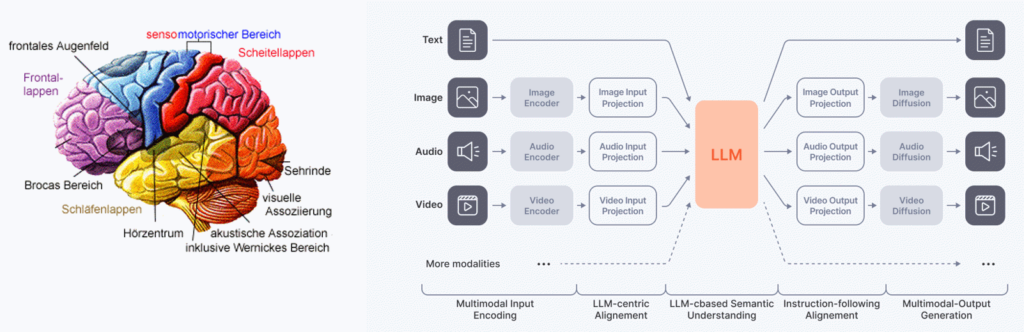
Die Forschungsgruppe Multimodale Künstliche Intelligenz widmet sich dieser Aufgabe und benutzt die neuesten Basismodelle aus internationaler Forschung, um diese für Anwendungsfälle aus der regionalen Wirtschaft weiter zu entwickeln. Kleinere Modelle im Bereich Spracherkennung und Sprachsynthese werden dabei auch von Grund auf selbst entwickelt. In den meisten Fällen ist es aber energetisch und ökonomisch sinnvoll vortrainierte Modelle zu verwenden und diese nur auf deutsche Sprache oder die unternehmensspezifischen Anwendungsfälle fein zu tunen.
Trainingsdaten
Dazu ist nach wie vor das Erstellen qualitativ hochwertiger und quantitativ ausreichender Trainingsdaten ein zentrales Thema. Die Forschungsgruppe hat sich dahingehend umfassende Kompetenz im sammeln und qualitätssichern realer Daten, sowie im Erstellen synthetischer Trainingsdaten erarbeitet. Der Schlüssel liegt hier in der Nutzung der besten verfügbaren KI-Modelle um damit die Datenqualität und -quantität zu erhöhen und somit die nächst bessere Generation von KI-Modellen trainieren zu können. Dies führt zu einer Aufwärtsspirale, die auch das enorme Tempo erklärt, mit dem in den letzten Jahren Fortschritte im Bereich Deep Learning erzielt wurden.
Ressourceneffizienz
Ein Schwerpunkt unserer Arbeit liegt auf der Nutzung ressourcen-effizienter Verfahren, um sowohl beim Training als auch beim späteren operativen Betrieb die Umwelt zu schonen und auch Unternehmen mit kleinem Budget den Betrieb zu ermöglichen. Für Trainings verwenden wir daher parameter-effiziente Feintuning Verfahren wie Low Rank Adaptation (LoRA) und für den operativen Betrieb optimierte Laufzeitumgebungen, quantisierte Modelle und gut aufeinander abgestimmte und dadurch kosteneffiziente Hard- und Software.
Digitale Souveränität
Mit den von uns entwickelten Lösungen können Unternehmen selbst entscheiden, ob sie die KI-Modelle im eigenen Rechenzentrum, je nach Anwendungsfall sogar unter dem eigenen Schreibtisch, oder bei einem deutschen Cloudanbieter betreiben wollen. Es entstehen keine Abhängigkeiten zu multi-nationalen Konzernen. Wir achten bei der Auswahl der Modelle auf Offenheit, Transparenz und kommerzielle Verwendbarkeit.
Projekterfahrung
Mit den EFRE Technologie-Transfer-Projekten DAMMIT (Digitale Transformation des Mittelstands mit künstlicher Intelligenz) und M4-SKI (Multimodale Mensch-Maschine Schnittstelle mit KI) hat die Forschungsgruppe in über einem Dutzend Anwendungsfällen gezeigt, was praktisch möglich ist. In wenigen Fällen scheitern die Vorhaben auch trotz entsprechender Gegenmaßnahmen an unzureichenden oder zu uniformen Daten, so dass die Modelle zwar mit Daten ähnlich zu den Trainingsdaten gut sind, sich diese Genauigkeit nicht auf den praktischen Anwendungsfall übertragen lässt. Trotzdem ist es wichtig für Unternehmen hier fortlaufend die neuesten technischen Möglichkeiten für die Unterstützung des eigenen Geschäfts zu evaluieren, um nicht den Anschluss zu verpassen, wenn andere durch KI-Einsatz enorme Einsparungen oder Qualitätssteigerungen erzielen.
Dialogsysteme
Im Fokus der Forschungsgruppe stehen dabei Assistenzsysteme, die im Dialog mit dem Benutzer gemeinsam und iterativ hochwertige Arbeitsergebnisse erzielen. Egal ob mit Sprachein- und -ausgabe, in Kombination von Text und Bild oder Text mit numerischen oder anderweitig außergewöhnlichen Daten: die aktuellen Möglichkeiten zur Unterstützung von Arbeitsaufgaben, die bisher ausschließlich manuell zu erledigen waren, sind vielfältig. Sprechen sie uns gerne an, ob auch ihr Anwendungsfall von uns mit einem Demonstrator gelöst werden kann.
KI trifft Virtual Reality
Besonders interessant ist es, die Möglichkeiten multimodaler KI mit Virtual Reality als Benutzerschnittstelle zu kombinieren. Dabei kommen visuelles, Sprach- und Textverstehen zusammen und bieten insb. für die Aus- und Weiterbildung neue Möglichkeiten, die vor 10 Jahren noch als Science Fiction galten. Auch hier blickt die Forschungsgruppe auf jahrelange Erfahrung in der Erstellung von VR Lernanwendungen zurück und kann damit auf eine sehr seltene Kombination von Kompetenzen zurückgreifen, die uns zum idealen Forschungspartner für viele Anwendungsfälle macht.